

Image processing in Sympathy for Data
This is the second blog post in a series of posts on image processing using Sympathy for Data, our own tool for graphically programming data-flows. See the previous entry for an example of how you can read the time from an analog clock using only basic image processing building blocks. No programming required.
The task
When it comes to object recognition today most people think about deep learning and throw vast datasets onto deep machine learning algorithms — hoping that something will stick. One thing that all such algorithms have in common is that they all have a large number of parameters, requiring an even larger number of examples to be trained. There are two major costs associated with this approach: firstly the computational cost in training the datasets, usually using a single or a cluster of high-end graphic cards; and secondly the difficulty in acquiring large enough datasets to do the training with. Sure, there exists techniques for artificially extending existing datasets into larger ones in order to help against over fitting, but even these cannot handle the case of datasets with only a hand full of examples. With all the hype of deep learning it is easy to forget that earlier approaches to object recognition, while much more limited in what they could solve, did not suffer from these difficulties and can sometimes still be favourable to be used.
If we look back at when image recognition was first considered as a problem to be solved with computers we see that the problem was at-first greatly underestimated. Back in the summer of 1966 a very optimistic project was started at MIT using only the student summer workers that year and with the aim of solving the computer vision problem. As you can read in the PDF the final goal was, in hindsight, a quite ambitious one indeed:
“The final goal is OBJECT IDENTIFICATION which will actually name objects by matching them with a vocabulary of known objects”.
Needless to say, this task proved more complex that what was first imagined, and have since led the the creation of a whole field of research. It is not until recently, more than 50 years after that summer project that we can say that general purpose object recognition is a more or less solved or solvable problem.
In my previous image processing post we looked at a simple image processing task in reading the time from an analog clock, and showed how this could be solved using the image processing tools available in Sympathy for Data, all without having to write a single line of code. A major factor in this solution was by limiting ourselves only to images acquired in a very specific way. This solution generalizes more to industrial image processing such as eg. reading a pressure valve rather than doing general purpose like reading like a random clock you find on the side of a building.
In this and the upcoming image processing post I will show how we can use the image processing tools and the machine learning tools of Sympathy to similarly solve an object recognition task under well defined circumstances. These circumstances generalizes again more to an industrial setting, such as analysing objects on a conveyor belt, where we can have a clearly defined environment and camera setup.
For this purpose we will have a camera mounted straight above the incoming objects. The objects are photographed against a neutral background (white) clearly distinguishable from the objects themselves (metallic grey). Furthermore we ensure that the lighting is smooth and even over the whole area and that no sharp shadows are cast by the objects themselves or anything else. In the example dataset used here we use pictures of a mix of fasteners, with the target of identifying the screws. Furthermore we ensure that objects are overlapping since it would require more advanced techniques to separate overlapping objects, a problem almost as hard as object recognition itself. If we would like to do this in an industrial setting we could use a mechanical solution to ensure this before the objects enter the belt, eg. using a suitable hopper.

Segmenting the image
We will start by solving the problem of segmenting and labelling an input image, with the task of deciding which areas of the image correspond to different objects. The intention here is to pick out individual objects and to classify each found object whether it matches the target object.
Thus our workflow will contain the following steps:
- Separate the image into pixels that belong to objects or to the background
- Cleanup this image to remove noise and to completely close all objects
- Create labels for each pixel
- Extract a list of binary image masks, one per found label.
A typical step in many image segmentation tasks is to use a simple thresholding algorithm. We can use simple thresholding and the fact that the metallic grey objects all are darker than the background paper in order to create a binary representation of the pixels that belong to objects. We start by attempting to use a simple basic threshold at the value 0.5.

Note that we added a filtering step that inverts the image by scaling it by a factor of -1 and adding an offset 1 to it before we do the thresholding. Thus we can ensure that a completely dark pixel (value 0) becomes 1.0 before thresholding and is classified as a “true” boolean after the thresholding.
We can also note that the result of the basic thresholding is quite poor, We incorrectly classify the bottom half of the image as belonging to an object. If we raise the threshold until no background is classified as an object, then we instead start losing pixels from the objects that are classified as background. You can see this effect in the images below, where we have a higher threshold on the right side than on the left side.

Furthermore, just using a simple scalar value as a hard-coded threshold will not work very well if there is even the slightest change in global illumination from picture to picture.
We can use one of the automatic thresholding algorithms that automatically finds a scalar suitable for thresholding. The simplest automatic thresholding algorithm is the mean or median which sets the threshold such that half the image will be True and half the image False. This is however seldom good, and most definitively not good for our application since we are almost guaranteed that background (which is more than 50% of the image) is classified as part of the objects.
Other alternatives to automatic thresholding include a number of algorithms that consider the overall distribution of pixel values and tries to find a suitable threshold. For example the Otsu algorithm assumes that the pixel values follows a bi-modal distribution and find a global threshold that minimises the variance within each found class.

The results of Otsu is surprisingly good for most images, as you can see in the image above. However we note that this algorithm still misses some parts of the objects (see the upper edge of the circular washers in the image above). Sometimes, it is impossible to get a good enough result by just setting a single global threshold value.
Other alternatives exists that perform an adaptive threshold that considers a window around each pixel and calculates a threshold value for that pixel based on this window. With this technique we for instance can easily compensate for any unevenness in the overall lighting.
One example of this is an adaptive gaussian thresholding method. Here we first perform a low pass filtering with a gaussian kernel of size 21 and sigma 11. We take the lowpass filtered value and apply an offset (-0.01) before testing if it is higher or lower than the pixel that is being thresholded. We picked the value for the kernel size based on the overall size of the objects (the circular ones are approximately 20 pixels wide). The offset compensates for small irregularities in the background itself.

The noise on the background can be removed in a later stage using morphological opening. Before we progress to this however we consider one more approach which is to instead extract all the edges in the image and to perform morphological operations to close the objects based on the edge data. We do this by applying a Canny edge detector to the raw input image (no pre-scaling step needed anymore). As we can see below this method generates no false positives and does capture all sides of the objects.

The interior of the objects can filled in using morphological closing after the Canny edge detector. What this does is to perform to perform a dilation operation followed by an erosion operation where the dilation makes all objects “thicker” by a given radius and the erosion makes them correspondingly “thinner”. Each of these operations are done by checking a neighbourhood around each pixel and taking the MAX or MIN value in the neighbourhood, respectively.
Consider the image on the left side below. In this image if we perform dilation then we get a white pixel in the areas marked red and green and only the area marked in blue would get a black pixel. If we instead perform erosion then we get black pixels in the red and blue areas and only the green area stays white. In the right side of the example below we can see the result of performing the erosion operation followed by a dilation operation. It has first made the white objects significantly thinner, followed by thicker.

For many objects making them thicker followed by thinner would not change the overall shape of the object. However, if two edges both become thick enough to touch each other then there is no black areas in the middle that can make them thinner again. Thus the end-result is that the objects have been closed as can be seen in the images below:
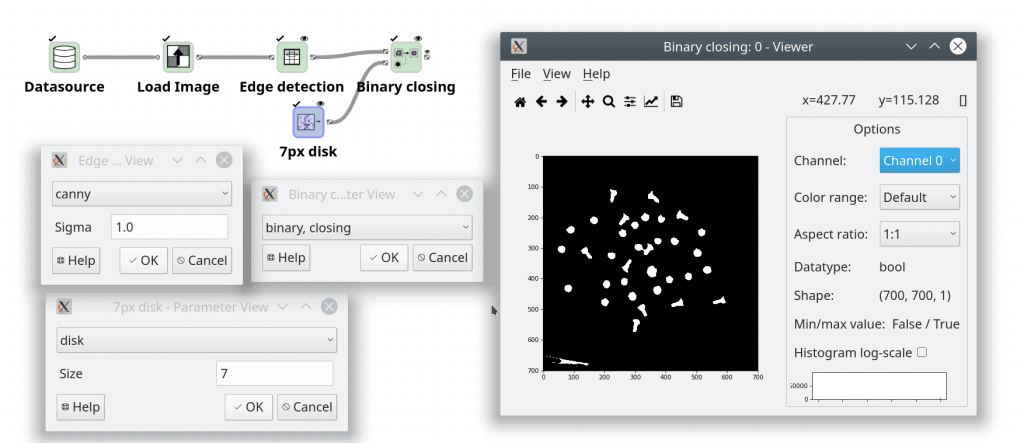
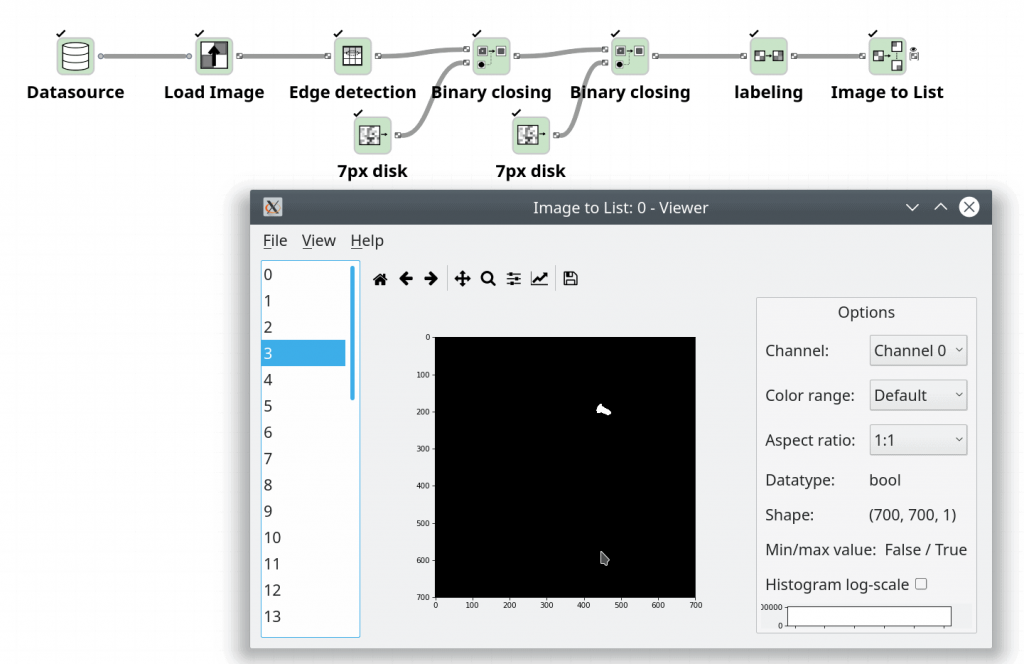
One problem that we can spot with the morphologically closed image is that some objects are now touching each other due to the thickening radius being larger that the distance between the objects which have created small bridges between some of the objects. To compensate for this we can perform a morphological opening that removes the small bridges between the objects. This step also removes all the small dots of false positives given by the thresholding algorithm if that one is used instead of the edge detection.
For the final step before we can start working with the objects it to use labeling to create a unique ID for each object. The labeling algorithm takes a binary image as input and creates an image with integers for each pixel. The integer values of a pixel correspond to a unique value for each object. If there were even a single pixel linking two objects to each other then both objects would be assigned the same integer value. We can visualise the result of this step by clicking on the object, this gives a pseudo-colour for each object based on a default colour map.
Note that since objects that are close to each other have similar ID’s then they are mapped to almost the same color. The ID values assigned differs even when not evident in the image below:

One final node that is useful is to create a list of all the found objects. The node Image to List can be used to convert the labeled image into a list of images. Use the configure menu to select “from labels” to do this conversion.
As we can see in the preview window below we have a list that contains many images. Each entry in the list is an image mask that is true only for one single object (as defined by the unique ID’s given by the labeling operation). We will use these images as the inputs to our classification algorithm to detect the individual objects.
Summary
In this post we have looked at the segmentation problem and shown how simple thresholding or edge detection algorithms can be used together with morphological operations and labeling to create a list of objects in an input image. This list of consists of a mask singling out each individual object in the image, one at a time. In part 2 we will continue to perform the classification of each found object.